图视频超分|CDFormer
【简要描述】
CDFormer是一个新颖的盲图像超分辨率(BSR)方法,名为Content-aware Degradation-driven Transformer。它旨在捕捉退化和内容表示,并通过引入基于扩散的模块来学习低分辨率和高分辨率图像中的内容退化先验(CDP),进而在低分辨率信息的基础上近似真实分布。此外,CDFormer应用了一个自适应的超分辨率网络,有效利用CDP来细化特征。与之前的基于扩散的超分辨率方法相比,CDFormer将扩散模型视为一个估计器,能够克服昂贵的采样时间和过度多样性的限制。实验表明,CDFormer在各种盲设置下的基准测试中超越了现有方法,建立了新的SOTA性能。
【算法地址】
【效果展示】

【算法特点】
- 利用内容退化先验(CDP)来增强低分辨率图像的内容细节。
- 采用自适应的超分辨率网络来细化特征。
- 将扩散模型作为估计器,以克服高采样时间和多样性的限制。
- 在多种盲设置基准测试中取得了SOTA性能。
图像生成应用|Compositional Text-to-Image Generation with Dense Blob Representations
【简要描述】
本工作提出了一种新的文本到图像的生成模型,名为BlobGEN,它使用密集的Blob表示来分解场景,这些表示包含场景的细粒度细节,同时具有模块化、易于构建和人类可解释的特点。BlobGEN利用了大型语言模型(LLMs)的组合性,通过一种新的上下文学习方法从文本提示中生成Blob表示。实验表明,BlobGEN在MS-COCO上实现了卓越的零样本生成质量和更好的布局引导可控性。
【算法地址】
【效果展示】

【算法特点】
- 提出了一种新的视觉布局,称为密集Blob表示,作为引导文本到图像生成的输入。
- Blob表示包含两个部分:1)Blob参数,它制定了一个倾斜的椭圆来指定对象的位置、大小和方向;2)Blob描述,是一个丰富的文本句子,描述对象的外观、风格和视觉属性。
- 通过现有的工具提取Blob表示(参数和描述),以指导文本到图像扩散模型。
- 设计了一个掩蔽交叉注意力模块,将每个Blob与其对应的视觉特征仅在其局部区域内关联。
- 利用了大型语言模型(LLMs)的组合性,通过一种新的上下文学习方法从文本提示中生成Blob表示。
深度学习底层|EfficientTrain++
【简要描述】
EfficientTrain++是一个即插即用的高效训练算法,用于训练基础视觉骨干网络。该算法简单、通用且效果显著,能够在不牺牲准确率的情况下,将多种流行模型(例如ResNet、ConvNeXt、DeiT、PVT、Swin、CSWin和CAFormer)在ImageNet-1K/22K上的训练时间减少1.5−3.0×。它同样适用于自监督学习(例如MAE)。
【算法地址】
【效果展示】


【算法特点】
- 在ImageNet-1K和ImageNet-22K上实现了1.5−3.0×无损训练或预训练加速。
- 对多种视觉骨干网络有效,包括ConvNets、各向同性/多阶段ViTs和ConvNet-ViT混合模型。
- 显著提高了相对较小模型的性能。
- 在不同的训练预算下都有出色的表现。
- 适用于监督学习和自监督学习。
- 为有限的CPU/内存能力优化了可选技术。
- 为大规模并行训练优化了可选技术。
深度学习底层|Efficient Vision-Language Pre-training by Cluster Masking
【简要描述】
该研究提出了一种简单的视觉-语言对比学习中的掩码策略,通过在训练的每次迭代中随机掩蔽视觉上相似的图像块,从而提高学习到的表示的质量和训练速度。这种策略通过原始像素强度测量,随机掩蔽视觉上相似的图像块集群。它为模型提供了额外的学习信号,因为它迫使模型仅从上下文中预测被掩蔽视觉结构的单词。此外,通过减少每个图像中使用的数据量,它还加快了训练速度。
【算法地址】
【效果展示】

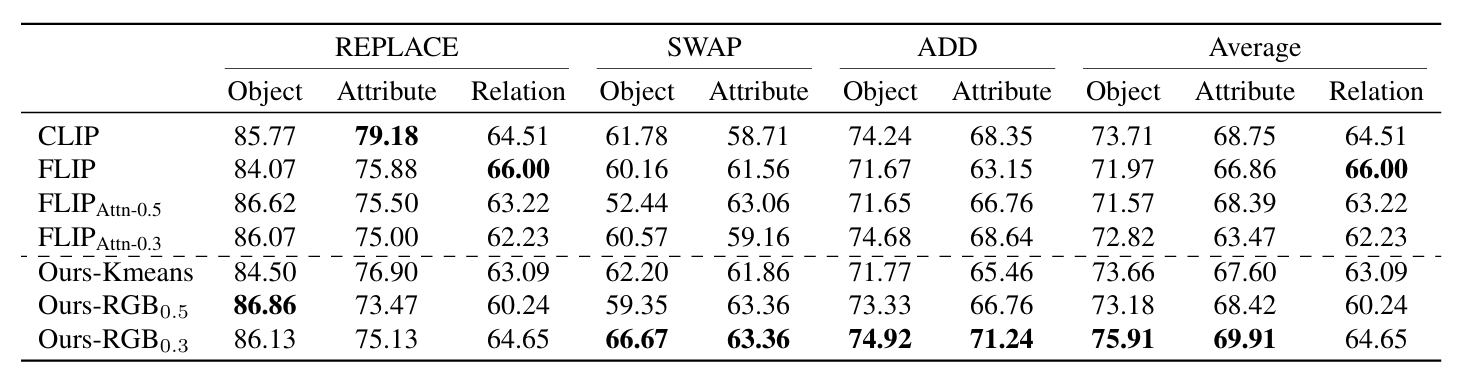
【算法特点】
- 通过随机掩蔽图像块集群来提高学习表示的质量和训练速度。
- 将图像分割成块,计算归一化块之间的成对余弦相似性。
- 使用Sugar-Crepe测试模型理解语言组合的能力,模型在关系测试中取得了可比的结果,并在对象和属性测试中表现出显著增强。
虚拟换装|GaussianVTON
【简要描述】
GaussianVTON是一个创新的3D虚拟试穿(VTON)流程,它整合了高斯散射(Gaussian Splatting, GS)编辑和2D VTON。该研究针对电子商务中虚拟试穿的重要性,提出了一种新的方法,使用图像作为3D编辑的提示(prompts),以实现从2D到3D VTON的无缝过渡。为了解决编辑过程中可能出现的问题,如面部模糊、服装不准确和视角质量下降,研究者设计了一个三阶段的细化策略来逐步减轻潜在问题。此外,引入了一种新的编辑策略,称为编辑回忆重建(Edit Recall Reconstruction, ERR),以解决以往编辑策略在导致复杂几何变化时的限制。
【算法地址】
【效果展示】
【算法特点】
- 通过多视点编辑将2D扩散模型适应于3D编辑。
- 使用图像作为3D编辑的提示,实现从2D到3D VTON的过渡。
- 提出了三阶段的细化策略,以解决编辑过程中的问题。
- 引入编辑回忆重建(ERR)策略,以处理复杂几何变化。
图像Low-level任务|Infinite Texture
【简要描述】
Infinite Texture是一种基于文本提示生成高分辨率纹理图像的方法,能够从单一文本提示生成任意大小的高质量纹理。这项技术特别适用于计算机图形学中,用于描述各种表面细节,如树干、人的皮肤等,有效提升图像的真实感。Infinite Texture的核心在于利用一个预训练的扩散模型,通过微调学习特定纹理的统计分布。首先,使用文本到图像的模型(如DALL-E 2)生成一个参考纹理样本。然后,该样本用于微调扩散模型,使其学习并嵌入参考纹理的统计特性。在生成阶段,通过分数聚合策略,该微调模型能够在单个GPU上生成任意分辨率的输出纹理图像**。此外,该方法还提出了一种基于扩散的策略,用于将生成的纹理应用于输入图像的重纹理。研究人员对Infinite Texture进行了消融研究,以评估模型各个组成部分的重要性,并与传统和基于深度学习的纹理合成方法进行了比较。通过在亚马逊机械土耳其(AMT)上进行的人类研究,定量评估了合成纹理的真实性。结果表明,Infinite Texture在合成纹理的任务中表现突出,被选择为最佳选项的比例为45%,远高于其他方法。此外,Infinite Texture还被应用于3D渲染和自然图像的纹理转移,展示了其在实际应用中的潜力和效果。尽管如此,该方法也存在局限性,比如可能会自动调整光照导致色彩漂移,或在处理具有强烈方向分布的纹理时表现不佳。
【算法地址】
【效果展示】

【算法特点】
- 文本提示生成:从单一文本提示生成任意大小的高质量纹理图像。
- 参考纹理样本:使用文本到图像的模型(如DALL-E 2)生成参考纹理样本。
- 分数聚合策略:在生成阶段,通过分数聚合策略,微调模型能够在单个GPU上生成任意分辨率的输出纹理图像。
- 纹理应用策略:提出了一种基于扩散的策略,用于将生成的纹理应用于输入图像的重纹理。
CTRLorALTer: Conditional LoRAdapter for Efficient 0-Shot Control & Altering of T2I Models
【简要描述】
LoRAdapter是一种新的方法,它通过一个新颖的条件LoRA块统一了风格和结构条件,实现了零样本控制。该方法是一种高效、强大且与架构无关的方法,用于调节文本到图像扩散模型,在生成期间实现细粒度的条件控制,并超越了最近的最先进方法。
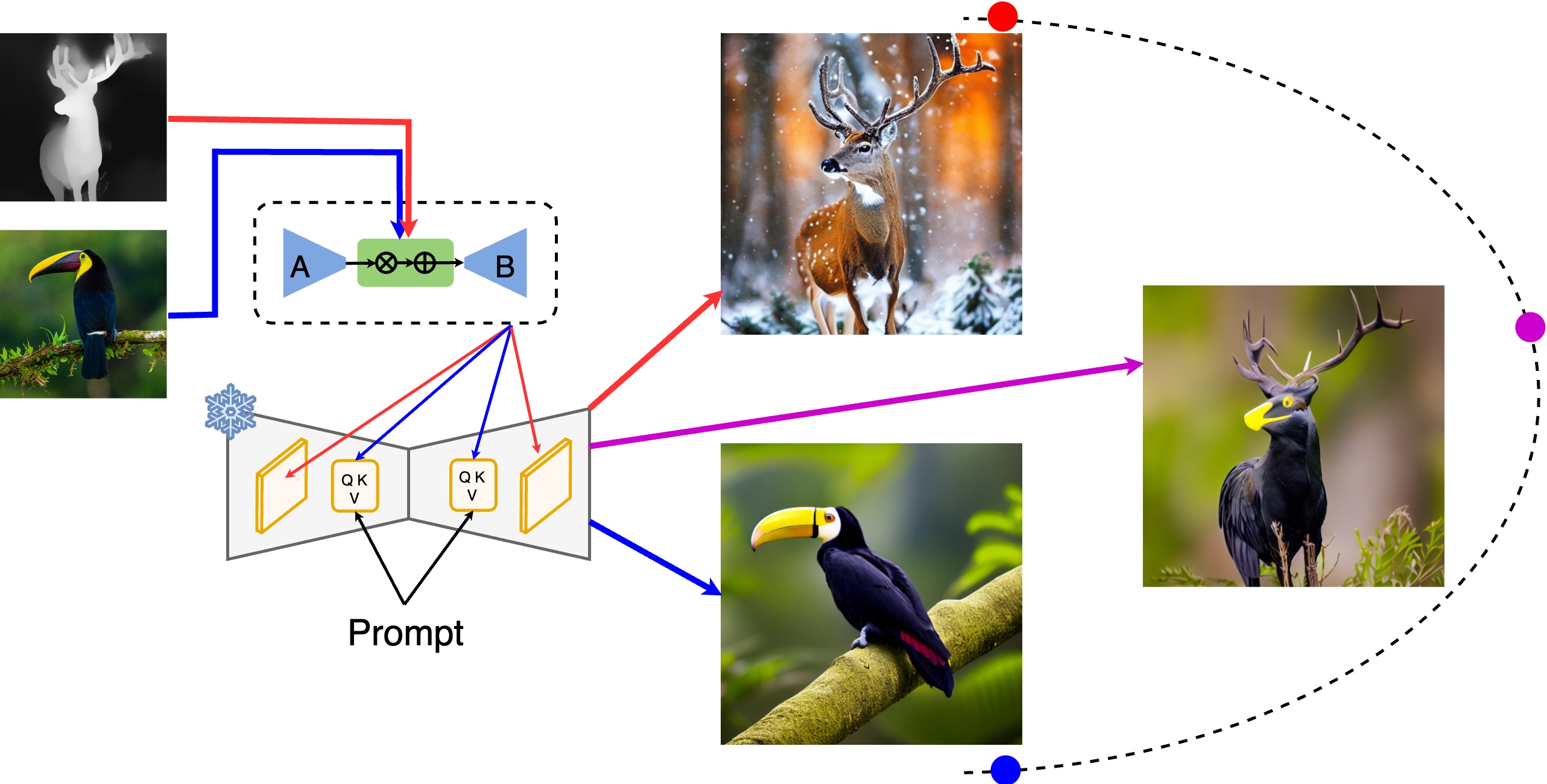
【算法地址】
【效果展示】


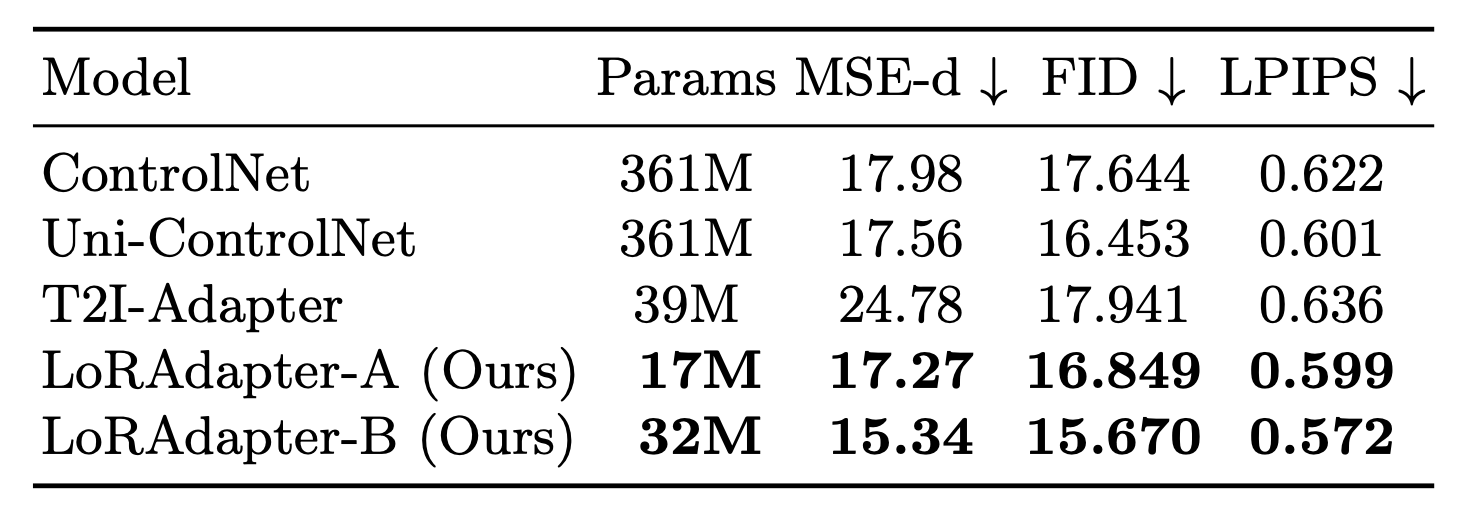
【算法特点】
- 使用标准的LoRA方法,保持原始权重矩阵W_0不变,并为要适应的每层(i)添加两个新的可训练权重矩阵A和B。
- 通过映射网络动态应用转换φ到第一个LoRA矩阵A的嵌入上,φ实现为具有缩放和平移参数γ和β的仿射变换。
- 在风格和结构条件的定性比较中,LoRAdapter与其它方法相比,在一些样本上表现更好。
- 在量化比较中,LoRAdapter在所有指标上超越了所有其他方法,并且需要的参数最少。