1. 图像生成内容优化|Face Adapter
【简要描述】
Face-Adapter 旨在解决当前稳定扩散(Stable Diffusion,简称SD)适配器在执行面部重演/交换时的不足表现。它特别关注于通过基于文本的属性控制来精确地跟踪目标结构,以及在面部交换中生成面部细节和处理面部形状变化。
【算法地址】
Face Adapter for Pre-Trained Diffusion Models with Fine-Grained ID and Attribute Control
【效果展示】


【算法特点】
● 完全解耦的身份(ID)、目标结构和属性控制,实现“一个模型,两个任务”。
● 简单而有效,即插即用。
● 与SD适配器相比,Face-Adapter 在面部重演和交换方面有显著的改进。
● 与基于扩散的方法相比,Face-Adapter 通过有效利用SD先验和提高生成质量来区别自己。
● 与基于生成对抗网络(GAN)的方法相比,Face-Adapter 在适应大姿态和面部形状变化方面表现出色,并在背景生成方面展现了卓越的性能。
2. 图像生成内容优化|DisenStudio
【简要描述】
DisenStudio 是一个创新的框架,它能够根据每个主体提供的少量图像生成文本引导的视频,并且可以为定制的多个主体生成视频。这个框架通过空间解耦的交叉注意力机制,将每个主体与期望的动作相关联,并采用运动保持的解耦微调方法,确保在静态图像上微调时能够保持时间运动生成能力。
【算法地址】
【效果展示】
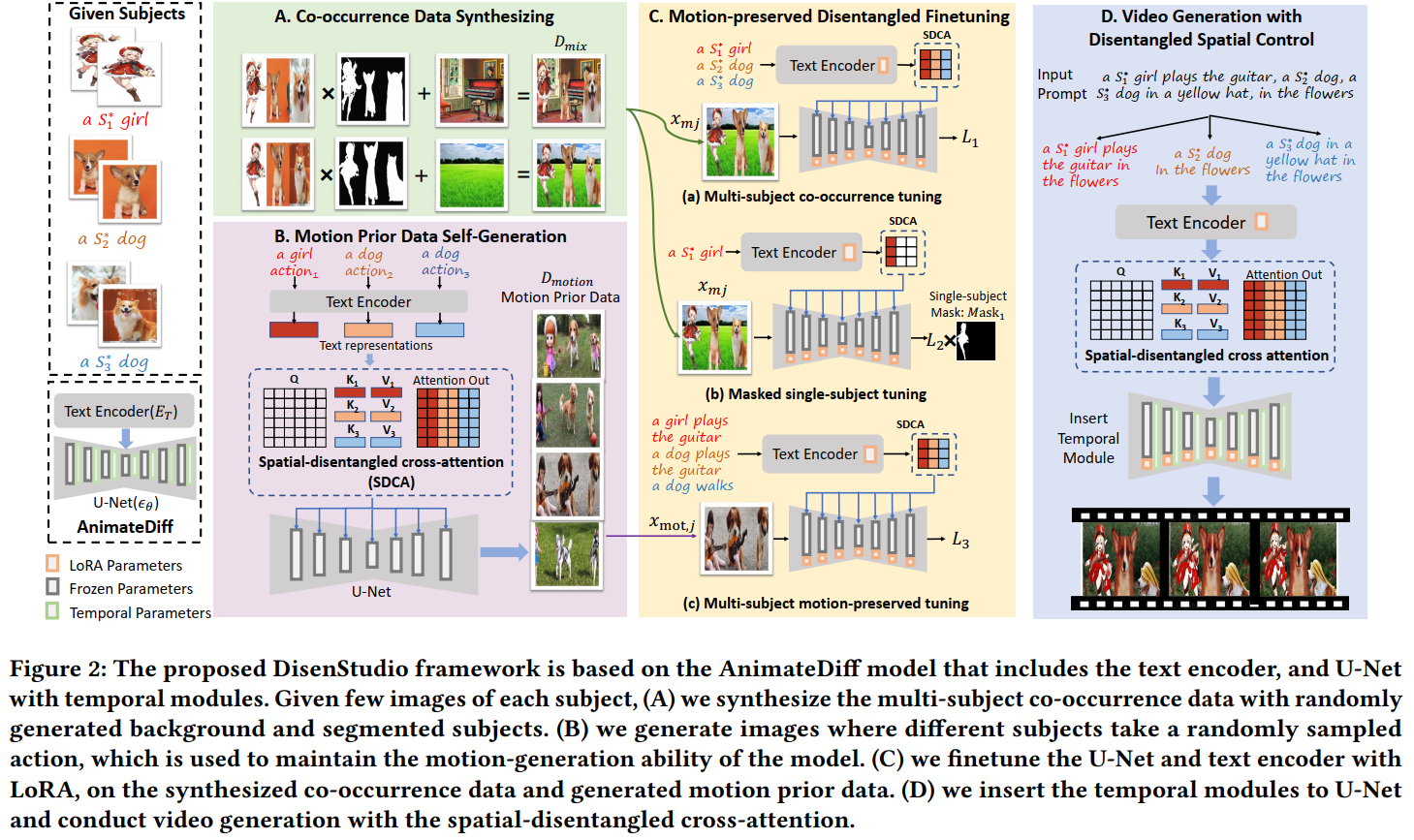
【算法特点】
● 能够为多个主体生成视频,同时遵循新的文本提示。
● 通过空间解耦的交叉注意力机制,将每个主体与期望的动作相关联。
● 采用运动保持的解耦微调方法,包括多主体共现微调、掩蔽单主体微调和多主体运动保持微调。
3. 图像-音频多模态|Images that Sound
【简要描述】
“Images that Sound” 是一个创新的项目,它使用扩散模型生成既看起来像自然图像又听起来像自然声音的频谱图。这种方法简单且无需训练,利用预训练的文本到图像和文本到频谱图扩散模型在共享潜在空间中操作。通过定量评估和感知研究,该方法成功生成了与期望音频提示相符的频谱图,同时也具有期望图像提示的视觉外观。
【算法地址】
【效果展示】

【算法特点】
● 零样本(zero-shot),无需训练或微调。
● 利用预训练的文本到图像和文本到频谱图扩散模型。
● 通过迭代去噪过程,使用频谱图扩散模型和图像扩散模型生成清洁的潜在表示。
● 将清洁的潜在表示解码成频谱图,并使用预训练的声码器转换为波形。
4. 3D换装|GarmentDreamer: 3DGS Guided Garment Synthesis with Diverse Geometry and Texture Details
【简要描述】
本文介绍了一种名为GarmentDreamer的新型3D服装合成框架,旨在通过文本提示定制仿真就绪的高质量带纹理的3D服装网格。传统的3D服装创建过程既耗时又昂贵,涉及绘制草图、建模、UV映射和纹理贴图等步骤。GarmentDreamer利用基于扩散的生成模型,从文本提示中生成3D服装,克服了现有方法中多视图图像不一致或需要额外处理步骤的问题。GarmentDreamer采用3D高斯溅射(3DGS)作为指导,通过粗到细的优化方法生成具有多样化几何和纹理细节的可穿戴3D服装网格。该方法首先利用扩散模型和物理模拟生成平滑的服装模板网格,然后通过3DGS指导的服装增强模块进行几何细节的优化。此外,引入了隐式神经纹理场(NeTF)和变分分数蒸馏(VSD)技术,以生成高质量的服装纹理。与传统的基于2D缝纫图案的方法相比,GarmentDreamer能够直接从文本生成细节丰富的服装,无需依赖2D图案。
【算法地址】
GarmentDreamer: 3DGS Guided Garment Synthesis with Diverse Geometry and Texture Details
【效果展示】

5. 图像生成内容优化|Evolving Storytelling: Benchmarks and Methods for New Character Customization with Diffusion Models
【简要描述】
本文探讨了如何将新角色有效地融入现有叙事中,并保持角色一致性的问题,特别是在数据有限的情况下。作者指出,现有的故事可视化生成模型在整合新角色时存在两大限制:缺乏合适的基准测试和新旧角色区分的挑战。为了解决这些问题,作者提出了”NewEpisode”基准测试,包含经过改进的数据集,用于评估生成模型在仅使用单一示例故事生成新故事的能力。作者引入了”EpicEvo”方法,这是一种定制的扩散模型,用于视觉故事生成。”EpicEvo”通过一个新颖的对抗性角色对齐模块,在扩散过程中逐步对齐生成图像与新角色的示例图像,同时应用知识蒸馏来防止忘记角色和背景细节。这种方法使得模型能够学习如何生成包含现有角色和/或新角色的故事,并且通过对抗性角色对齐模块鼓励模型独特地生成角色,并通过从预训练模型中提取知识来保持模型先验。
【算法地址】
【效果展示】
6. 图像生成质量优化|TriLoRA: Integrating SVD for Advanced Style Personalization in Text-to-Image Generation
【简要描述】
本文提出了一种名为TriLoRA的新方法,旨在改进文本到图像生成模型的微调过程,以实现更高级的风格个性化。现有的深度学习模型,如Stable Diffusion,在视觉艺术创作中应用广泛,但面临过拟合、生成结果不稳定和难以精确捕捉创造者所需特征等挑战。TriLoRA通过将奇异值分解(SVD)整合到低秩适应(LoRA)参数更新策略中,有效降低了过拟合风险,增强了模型输出的稳定性,并更准确地捕捉到创造者所需的微妙特征调整。TriLoRA是在LoRA框架内引入SVD的概念,通过训练两个适配器:一个标准低秩适配器(LoRA)和一个更小的适配器,这两个适配器相对于原始预训练权重并行训练。该方法的创新之处在于使用紧凑奇异值分解(Compact SVD)来确定创造者关注的特定特征数量,从而提供更精确的选择空间。在TriLoRA框架中,通过将Compact SVD整合到LoRA中,优化了权重矩阵的更新,使得模型在保持较低参数数量的同时,提高了对新任务的适应性。
【算法地址】
【效果展示】
7. 音频生成|Diff-BGM: A Diffusion Model for Video Background Music Generation
【简要描述】
本文提出了一个名为Diff-BGM的框架,旨在解决视频背景配乐生成的挑战。视频背景音乐生成任务面临多个难题,包括缺乏合适的训练数据集、难以灵活控制音乐生成过程以及视频和音乐的顺序对齐。为了解决这些问题,研究者们首先创建了一个高质量的音乐视频数据集BGM909,它包含详细的注释和镜头检测,提供视频和音乐的多模态信息。接着,提出了评估音乐质量的指标,包括音乐多样性和音乐与视频之间的对齐度,以及检索精度指标。Diff-BGM框架使用不同的信号来控制音乐生成过程中的不同方面。具体来说,它利用动态视频特征来控制音乐节奏,使用语义特征来控制旋律和氛围。此外,通过引入一个段感知的交叉注意力层,Diff-BGM能够顺序地对齐视频和音乐。该框架采用扩散模型作为基础,通过迭代添加高斯噪声的方式逐步破坏数据结构,并在去噪过程中学习从噪声输入中重建原始结构。
【算法地址】
[2405.11913v1] Diff-BGM: A Diffusion Model for Video Background Music Generation
【效果展示】
8. 视频换装|ViViD: Video Virtual Try-on using Diffusion Models
【简要描述】
ViViD是一种新颖的视频虚拟试穿框架,利用扩散模型解决视频试穿中的时间一致性和视觉质量问题。该技术旨在将服装项目自然地融入目标人物的视频之中,同时保持源视频的其他部分不变。与以往基于图像的试穿技术相比,ViViD能够生成高分辨率、逼真且与人体动作一致的试穿视频。ViViD框架包括一个服装编码器(Garment Encoder),用于提取服装的细粒度语义特征,并通过注意力特征融合机制将这些特征注入目标视频中。此外,该框架引入了一个轻量级的姿态编码器(Pose Encoder),以编码姿势信号,使模型能够学习服装与人体姿势之间的交互,并在文本到图像的稳定扩散模型中插入时间模块,以实现更连贯、更逼真的视频合成。
【算法地址】
ViViD: Video Virtual Try-on using Diffusion Models
【效果展示】
9. 视频生成|FIFO-Diffusion: Generating Infinite Videos from Text without Training
【简要描述】
本文提出了一种名为FIFO-Diffusion的新颖推理技术,该技术基于预训练的扩散模型,用于文本条件视频生成。FIFO-Diffusion能够生成无限长度的视频,而无需再训练。该方法通过迭代执行对角去噪,同时处理一系列连续帧,这些帧在队列中的噪声水平逐渐增加。FIFO-Diffusion通过在头部出队一个完全去噪的帧,同时在尾部入队一个新的随机噪声帧来实现视频的生成。FIFO-Diffusion的核心在于对角去噪,它通过队列维护具有单调递增噪声水平的帧序列。尽管对角去噪在利用前向参考的优势方面存在双重效应,但为了减少训练与推理之间的差距,文章引入了潜在分割和前瞻去噪技术。潜在分割通过增加离散化步骤来减少噪声水平的差异,而前瞻去噪则利用对角去噪的优势,特别是在对后半部分噪声较大的帧进行去噪时。此外,这两种技术都能够在多个GPU上并行化推理,提高了效率。
【算法地址】
【效果展示】
10. 图像重建|CAT3D: Create Anything in 3D with Multi-View Diffusion Models
【简要描述】
CAT3D是一种创新的3D场景创建方法,它利用多视图扩散模型模拟现实世界的捕获过程。与传统的3D重建技术相比,CAT3D能够从任意数量的输入图像生成高度一致的新视图,并将这些视图作为输入,通过稳健的3D重建技术产生可以在任何视点实时渲染的3D表示。这项技术不仅大幅减少了创建3D场景所需的时间和资源,而且在质量和效率上都超越了现有的单图像和少视图3D场景创建方法。CAT3D的核心是一个两步3D创建流程。首先,它使用多视图扩散模型生成与一个或多个输入视图一致的大量新视图。其次,将这些生成的视图输入到一个稳健的3D重建流程中,以学习NeRF表示,从而允许从任何视点渲染3D场景。该方法的关键是在模型架构中使用3D自注意力和相机姿态嵌入,以及通过高效的并行采样策略生成3D一致的图像集合。此外,CAT3D还改进了标准的NeRF训练过程,以提高对不一致输入视图的鲁棒性。
【算法地址】
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
【效果展示】
11. Low-level|Deep Data Consistency: a Fast and Robust Diffusion Model-based Solver for Inverse Problems
【简要描述】
本文提出了一种名为Deep Data Consistency (DDC)的新型扩散模型,用于解决逆问题。逆问题在图像处理中十分常见,如超分辨率、修复、去模糊等。DDC通过深度学习模型更新数据一致性步骤,有效平衡了数据一致性和图像的真实性,同时显著提高了采样速度,解决了传统扩散模型在广泛应用中的障碍。DDC的核心在于使用变分界限训练目标来最大化条件后验概率,同时减少对扩散过程的影响。该方法通过分析现有技术,创新性地设计了网络的训练目标,使得在训练过程中数据能够逼近真实图像,同时最小化对扩散过程的干扰。DDC采样算法简单高效,仅需要5个推理步骤即可完成图像的恢复。
【算法地址】
【效果展示】
12. Low-level|Hierarchical Neural Operator Transformer with Learnable Frequency-aware Loss Prior for Arbitrary-scale Super-resolution
【简要描述】
本文提出了一种任意尺度的超分辨率(SR)方法,旨在增强科学数据的分辨率。这些数据通常涉及连续性、多尺度物理和高频信号等复杂挑战。该方法基于算子学习,具有分辨率不变性。模型的核心是一个层次化的神经算子,它利用Galerkin型自注意力机制,高效地学习函数空间之间的映射。此外,引入了一种从输入数据的频谱重置中派生的可学习先验结构,该结构是模型无关的,并设计为动态调整像素贡献的权重,有效平衡模型中的梯度。为了解决现有任意尺度SR方法中的挑战,如低分辨率特征、频谱偏差和损失函数的局限性,作者提出了一种混合方法。该方法结合了传统的卷积上采样和频谱上采样,以增强性能。此外,将SR重新定义为算子学习问题,用神经算子替代了基于MLP的推理网络。作者提出的层次化变换器作为一个神经算子,用于学习这些函数空间之间的映射。对于损失函数的挑战,提出了一种基于频谱重置的损失先验,该先验设计为调整图像空间内每个像素对整体损失的贡献。
【算法地址】
【效果展示】
13. 视频摘要|”Previously on …“ From Recaps to Story Summarization
【简要描述】
本文提出了一种基于电视节目回顾片段的多模态故事摘要生成方法。电视节目回顾(即上集回顾、前情提要)是一种在新剧集开始前,通过快速剪辑关键场景和对话来帮助观众回顾前情的短片。研究者们利用这些回顾片段作为标签,来识别和扩展剧集中的重要子故事,从而生成故事摘要。这种方法不仅能够提取视频中的关键画面,还能识别对话中的重要元素,以构建一个完整的故事摘要。研究者们提出了一个名为PlotSnap的数据集,该数据集包含两部犯罪惊悚电视剧,每集长约40分钟,具有丰富的剧情回顾。他们提出了一个名为TaleSumm的层次化模型,该模型通过创建紧凑的视频镜头和对话表示,处理整个剧集,并预测每个视频镜头和对话的重要性分数。TaleSumm模型的特点是能够在局部故事组内促进镜头和对话之间的交互,同时通过群组标记实现故事组间的信息传递。
【算法地址】
【效果展示】
14. 3D生成|ART3D: 3D Gaussian Splatting for Text-Guided Artistic Scenes Generation
【简要描述】
本文介绍了ART3D,一个创新的框架,用于生成3D艺术场景。ART3D结合了扩散模型和3D高斯溅射技术,通过文本描述输入,能够渲染具有一致视角的3D图像。该方法通过图像语义转移算法有效地弥合了艺术图像与现实图像之间的差距,并引入了深度一致性模块以增强3D场景的一致性。实验结果表明,与现有方法相比,ART3D在内容和结构一致性指标上表现更优,显著推动了AI在艺术创作领域的进展。ART3D利用了Stable Diffusion模型的强大生成能力,并提出了一种创新的3D高斯溅射技术,通过更新点云图来从用户提供的文本输入生成艺术性的3D场景。具体来说,ART3D提出了一种图像语义转移算法,以弥合艺术与现实图像之间的差距。该算法从用户提供的文本或参考图像中提取具有相同语义布局的特征图,然后使用文本提示生成新的现实图像,确保它们遵循相同的语义布局。通过深度图和初始艺术图像生成初始点云,成功解决了艺术与现实图像之间的域差异。此外,引入深度一致性模块,通过调整深度域,确保新生成的点云与整个系统无缝集成,提高多视图生成的一致性。